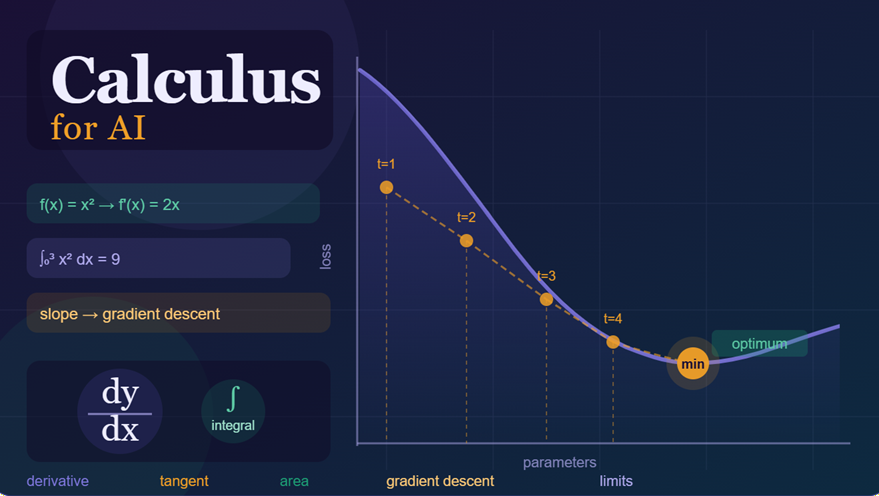
Calculus is the mathematical study of continuous change. Linear algebra deals with static numbers, and geometry deals with shapes. Calculus allows us to compute rates of change (such as speed or acceleration) and the accumulation of quantities (such as total distance or volume) over time.
What is Calculus?
Calculus deals with the continuous change of functions. It is broadly divided into two main branches:
1. Differential Calculus
Differential calculus is the rate of change of a quantity. In differential calculus, we discuss the derivative, which represents the exact steepness or slope or instantaneous rate of change of a function at a specific point.
Real-world Example: Finding the exact speed of a car at a split second using your speedometer is differential calculus.
2. Integral Calculus
Integral calculus studies the accumulation of quantities, which means integration to find the total size, volume, or area under a curve by adding together infinitely many tiny, continuous pieces.
Real-world Example: Calculating the total distance a car travels from point A to point B based on a changing speed using an odometer is integral calculus.
The differentiation and integration are inverse operations – just as multiplication and division are inverses of each other.
Why Calculus Matters in AI?
Calculus matters a lot in AI model training for 3 reasons:
- Accuracy Improvement: Calculus is essential for training models and improving their accuracy.
- Error Minimization: It enables algorithms to compute the error rate and adjust parameters to reduce it.
- Predictive Power: It helps in optimizing the training process and improves the speed and quality of AI predictions.
Core Calculus Concepts Every Data Scientist Must Know
1. Functions and Limits
A function maps an input value to an output value. For example, f(x) = x². Before understanding derivatives, you must understand limits.
A limit describes the value a function approaches as the input approaches a particular point. It is the foundation on which derivatives and integrals are built.
Example: As x approaches 2, the function f(x) = x² approaches 4. We write this as:
lim (x → 2) x² = 4
In machine learning, limits help us understand how the model’s error changes if we make infinitely small adjustments to the model’s parameters.
2. Derivatives: The Heart of Model Training
A derivative measures how much a function changes when its input changes. Formally, it is the instantaneous rate of change of a function at a specific point.
Notation: The derivative of f(x) is written as f'(x) or df/dx.
Geometric meaning: The derivative at a point is the slope of the tangent line to the curve at that point.
Basic Derivative Rules
| Rule | Formula | Example |
|---|---|---|
| Power Rule | d/dx (xⁿ) = n·xⁿ⁻¹ | d/dx (x³) = 3x² |
| Constant Rule | d/dx (c) = 0 | d/dx (5) = 0 |
| Sum Rule | d/dx (f+g) = f’ + g’ | d/dx (x²+x) = 2x+1 |
| Chain Rule | d/dx f(g(x)) = f'(g(x))·g'(x) | d/dx (x²+1)² = 2.(x²+1).2x Used in backpropagation |
| Product Rule | d/dx (f·g) = f’g + fg’ | d/dx (x²+7)(3x²+2) = 2x(3x²+2) + (x²+7)6x Used in loss functions |
Common Derivatives a Data Scientist Must Know
| Function (f(x)) | Derivative (f'(x)) | Where Used |
|---|---|---|
| c | (0) | Constant term |
| x | (1) | Linear models |
| xⁿ | n · xⁿ⁻¹ | Polynomial regression |
| √x | 1 / (2√x) | Feature transformations |
| 1/x | 1/x² | Optimization |
| eˣ | eˣ | Neural Networks |
| aˣ | aˣ · ln(a) | Growth models |
| ln(x) | 1/x | Log Loss, Likelihood |
| log_a(x) | 1 / (x · ln(a)) | Information Theory |
| sin(x) | cos(x) | Signal Processing |
| cos(x) | -sin(x) | Fourier Analysis |
| tan(x) | sec²(x) | Mathematical Modeling |
| sigmoid σ(x) = 1/(1+e⁻ˣ) | σ(x) · (1 − σ(x)) | Logistic Regression, Neural Networks |
| tanh(x) | 1 − tanh²(x) | Deep Learning |
| (max(0,x)) (ReLU) | (0) if (x<0), (1) if (x>0) | Deep Learning |
Why Derivatives Matter in Machine Learning?
Every time a neural network trains, it uses derivatives to answer one question: “How should I adjust my weights to reduce the error?”
The derivative of the loss function with respect to each weight tells the model exactly how much to adjust and in which direction. This process is called backpropagation, and that’s 100% calculus.
3. Partial Derivatives
In machine learning, models have thousands or millions of parameters, not just one variable. A partial derivative measures how a function changes with respect to one variable while holding all other variables constant.
Notation: ∂f/∂x (pronounced “partial f, partial x”)
Example: If your loss function L depends on weights w₁ and w₂:
- ∂L/∂w₁ tells you how the loss changes when you adjust w₁ (keeping w₂ fixed)
- ∂L/∂w₂ tells you how the loss changes when you adjust w₂ (keeping w₁ fixed)
The collection of all partial derivatives is called the gradient, the most important concept in model optimisation.
4. Gradient Descent: Calculus in Action
Gradient Descent is the optimisation algorithm that powers almost every machine learning model. It uses the product rule of derivatives to iteratively reduce the model’s error.
The intuition: Imagine you are standing on a hilly landscape in fog. You cannot see the whole landscape; you can only feel the slope under your feet. Gradient descent takes one small step downhill at each iteration until you reach the lowest point: the minimum error.
The formula:
w_new = w_old - α × ∂L/∂w
Where:
- w = model weight (parameter)
- α = learning rate (step size — how big a step you take)
- ∂L/∂w = derivative of the loss function with respect to the weight
Three variants used in practice:
| Type | How it works | Used when |
|---|---|---|
| Batch Gradient Descent | Uses all training data per step | Small datasets |
| Stochastic Gradient Descent (SGD) | Uses one sample per step | Large datasets |
| Mini-batch Gradient Descent | Uses a small batch per step | Most neural networks |
5. The Chain Rule: How Neural Networks Actually Learn
The Chain Rule is the most important calculus rule for deep learning. It allows us to compute the derivative of a composite function, which is a function built from other functions.
Formula: If y = f(g(x)), then:
dy/dx = f'(g(x)) × g'(x)
Why it matters for neural networks: A neural network is simply a chain of functions, i.e., one layer feeds into the next. The chain rule allows us to compute how the error at the output layer propagates all the way back through every layer to every weight. This is backpropagation, and without the chain rule it would be impossible.
6. Integrals: Area Under the Curve
An integral computes the total accumulation of a quantity. Geometrically, it is the area under a curve between two points.
Notation: ∫ f(x) dx
Two types:
- Definite integral: Computes the area between two specific points (gives a number)
- Indefinite integral: Finds the general antiderivative of a function (gives a function)
Where Integrals Appear in Data Science
Probability distributions: The area under a probability density function (PDF) between two values gives you the probability of a variable falling in that range. For example, the area under a Normal distribution curve between -1 and +1 standard deviations equals approximately 68%.
P(-1 < x < 1) = ∫₋₁¹ f(x) dx ≈ 0.68
Expected value: The average value of a continuous random variable is computed using integration, central to Bayesian statistics and probabilistic machine learning.
7. Calculus in Python: Hands-On
You do not need to solve calculus by hand as a data scientist. Python libraries handle the computation. Here is how:
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
from scipy import integrate
# 1. Define a function
def f(x):
return x**3 - 3*x**2 + 2
x = np.linspace(-1, 4, 300)
y = f(x)
# 2. Compute derivative at a specific point
x0 = 2.0
dy_dx = derivative(f, x0, dx=1e-6)
print(f"Derivative of f(x) at x={x0}: {dy_dx:.4f}")
# 3. Plot the function and its tangent line
tangent_y = f(x0) + dy_dx * (x - x0)
plt.figure(figsize=(10, 5))
plt.plot(x, y, 'b-', linewidth=2, label='f(x) = x³ - 3x² + 2')
plt.plot(x, tangent_y, 'r--', linewidth=1.5, label=f'Tangent at x={x0}')
plt.axhline(0, color='black', linewidth=0.5)
plt.axvline(0, color='black', linewidth=0.5)
plt.scatter([x0], [f(x0)], color='red', zorder=5)
plt.title('Function and Its Derivative (Tangent Line)', fontsize=13, fontweight='bold')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('calculus_derivative.png', dpi=150)
plt.show()
print("Plot saved!")
# 4. Compute a definite integral
result, error = integrate.quad(f, 0, 3)
print(f"\nDefinite integral of f(x) from 0 to 3: {result:.4f}")
print(f"Estimated error: {error:.2e}")
# 5. Gradient Descent from scratch
print("\n Gradient Descent Demo ")
def loss(w):
"""Simple loss function: L(w) = w² - 4w + 5"""
return w**2 - 4*w + 5
def grad_loss(w):
"""Derivative of loss: dL/dw = 2w - 4"""
return 2*w - 4
w = 10.0 # starting weight
alpha = 0.1 # learning rate
iterations = 30
print(f"{'Iteration':<12} {'Weight (w)':<15} {'Loss':<12}")
print("-" * 40)
for i in range(iterations):
grad = grad_loss(w)
w = w - alpha * grad
if i % 5 == 0:
print(f"{i:<12} {w:<15.6f} {loss(w):<12.6f}")
print(f"\nMinimum found at w = {w:.4f}")
print(f"Minimum loss value = {loss(w):.6f}")
print("True minimum at w = 2.0 (verified by calculus: dL/dw = 0 → w = 2)")
Expected output:
Derivative of f(x) at x=2.0: 0.0000
Definite integral of f(x) from 0 to 3: 2.2500
Gradient Descent Demo
Iteration Weight (w) Loss
----------------------------------------
0 8.400000 50.760000
5 4.262144 2.134...
10 2.671088 1.449...
15 2.214748 1.046...
20 2.068719 1.004...
25 2.021990 1.000...
Minimum found at w = 2.0068
Minimum loss value = 1.000046
True minimum at w = 2.0 (verified by calculus: dL/dw = 0 → w = 2)
How Calculus Connects to the Full Data Science Stack
Calculus does not exist in isolation. It is the final piece of the mathematical foundation that connects everything:
| Concept | Calculus connection |
|---|---|
| Linear Algebra | Matrix operations define the structure; calculus optimises it |
| Probability & Statistics | Probability density functions require integration |
| Machine Learning | Every model trains using gradient descent (derivatives) |
| Neural Networks | Backpropagation uses the chain rule at every layer |
| Natural Language Processing | Transformer attention mechanisms use derivatives for training |
| Computer Vision | Convolutional neural networks optimise using calculus |
Calculus Roadmap for Data Scientists
Follow this learning order:
- Functions and Limits: understand what a function is and how limits work
- Derivatives: power rule, chain rule, product rule
- Partial Derivatives: extending derivatives to multiple variables
- Gradient and Gradient Descent: the optimisation algorithm of ML
- Integrals: area under curve, probability distributions
- Multivariable Calculus: Jacobian and Hessian matrices (advanced)
Summary
| Concept | What it does | Where it appears in AI |
|---|---|---|
| Derivative | Measures rate of change | Gradient descent, backpropagation |
| Partial Derivative | Rate of change for one variable | Multi-parameter optimisation |
| Chain Rule | Derivative of composite functions | Backpropagation in neural networks |
| Gradient | Direction of steepest increase | Optimising all ML models |
| Gradient Descent | Iterative error minimisation | Training every ML and DL model |
| Integral | Accumulation/area under curve | Probability distributions, Bayesian ML |
Stay Tuned!!
Calculus is one of five mathematical foundations every data scientist needs. Explore the complete series:
- Linear Algebra
- Coordinate Geometry
- Planes
- Matrices
- Calculus — you are here
Keep learning and keep implementing!!