Data Science is a multidisciplinary field that combines machine learning, deep learning, artificial intelligence, mathematics, and statistics. To learn more about these terms in detail click here.
In this article, we will go through the Data Science Project Lifecycle in detail.
What is a Data Science Project Lifecycle?
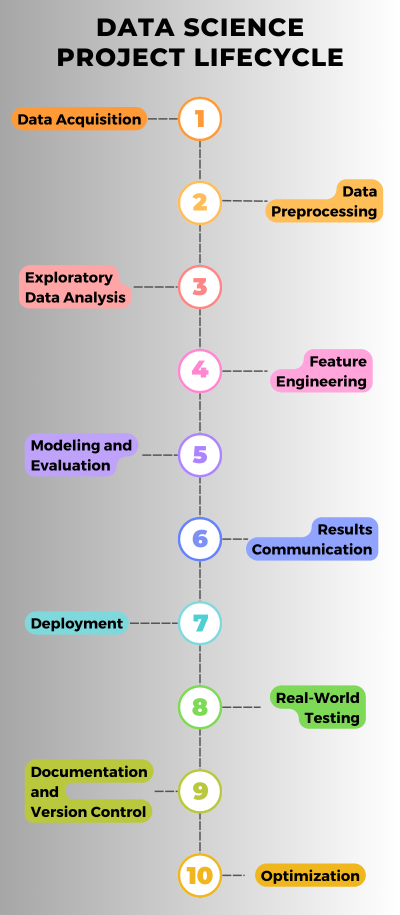
The Data Science Project Lifecycle is a project’s process to become a successful running project. At each stage, various processes and tools are involved. We divided the Data Science Project Lifecycle into 10 stages as listed below:
- Data Acquisition
- Data Preprocessing
- Exploratory Data Analysis
- Feature Engineering
- Modeling and Evaluation
- Results Communication
- Deployment
- Real-World Testing
Documentation and Version Control
- Optimization
Once the business understanding is done and the business problem is properly defined, we start with the first stage of the Data Science Project Lifecycle. Let’s discuss all of these steps in detail.
Data Acquisition
Data Acquisition consists of three parts Extract, transform, and load i.e. ETL process. Data is extracted from various sources and transformed into a format that can be examined and stored in the database or data warehouse for next usage. Various ETL tools are available like Hadoop, Apache Airflow, AWS Glue, etc. to simplify this process.

Data Preprocessing
Once we get the data, the following five preprocessing steps need to be done.
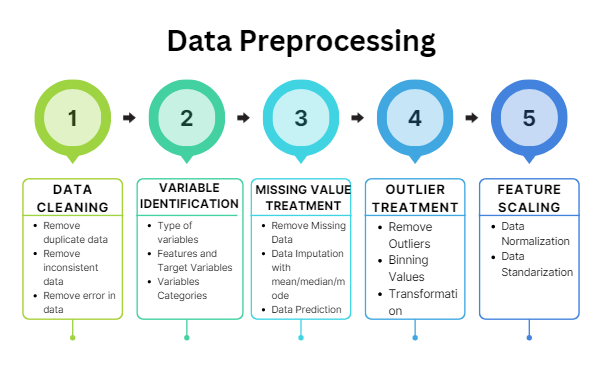
1. Data Cleaning
Data should be cleaned for any inconsistencies, errors, and duplicate data.
2. Variable Identification
Variable Identification is a three-step process.
- Identify the variables’ data type, i.e., int, float, string, object, character, etc. To learn about data types in Python, click here.
- Identify all input features and the target variable.
- Identify the category of each feature and target variable, i.e., Continuous or Categorical
3. Missing Value Treatment
To learn missing value treatment in detail, click here.
4. Outlier Data Treatment
Outliers can be detected using the IQR range and Box-Plot graphs. To learn about these techniques, click here. Outliers can be treated in four ways:
- By Removing Outliers
- By Mean/Median Imputation
- By Binning values by making groups
- By transforming values using logarithmic or trigonometric functions.
5. Feature Scaling
Feature Scaling is done for numerical features. Numerical features can be continuous or discrete.
Continuous numerical features like house prices, temperature, stock prices, etc.
Discrete numerical features are like the number of bedrooms, no. of years, number of employees, etc.
To learn feature scaling and its methods in detail, click here.
Exploratory Data Analysis
Exploratory data analysis is done to extract and visualize insights into the data, their distribution, relationship between variables. Statistical Analysis and Data Visualization methods are used for Univariate, bivariate, and multivariate analysis of the variables.
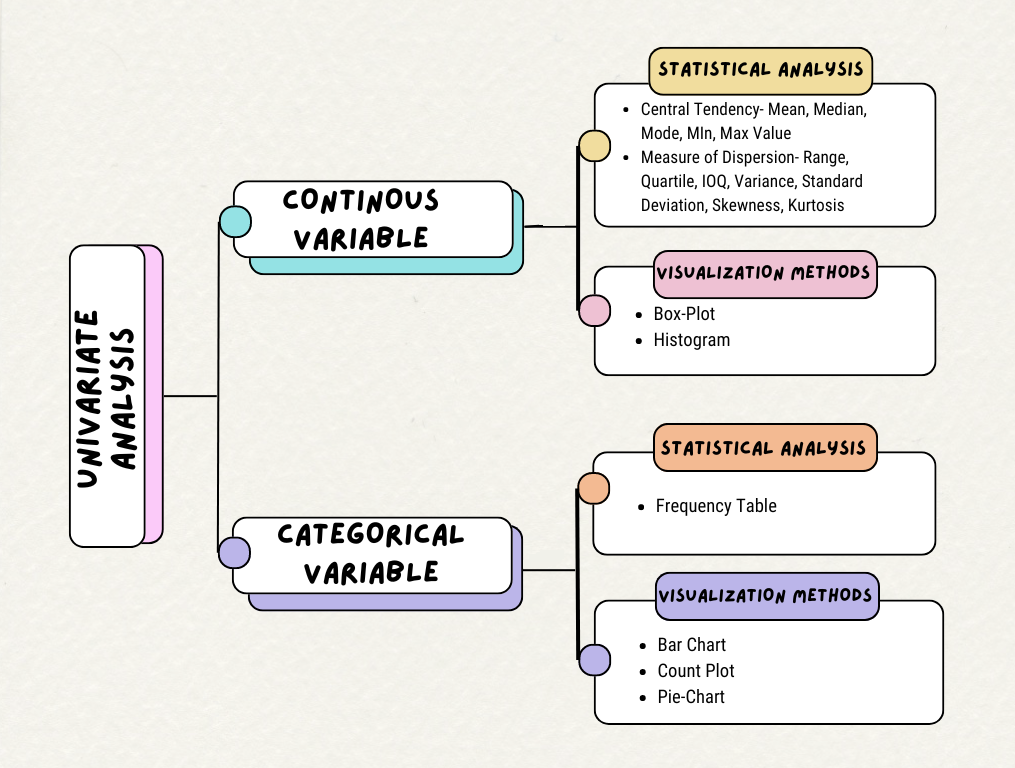
Univariate Analysis is used to analyze and extract properties of a single variable.
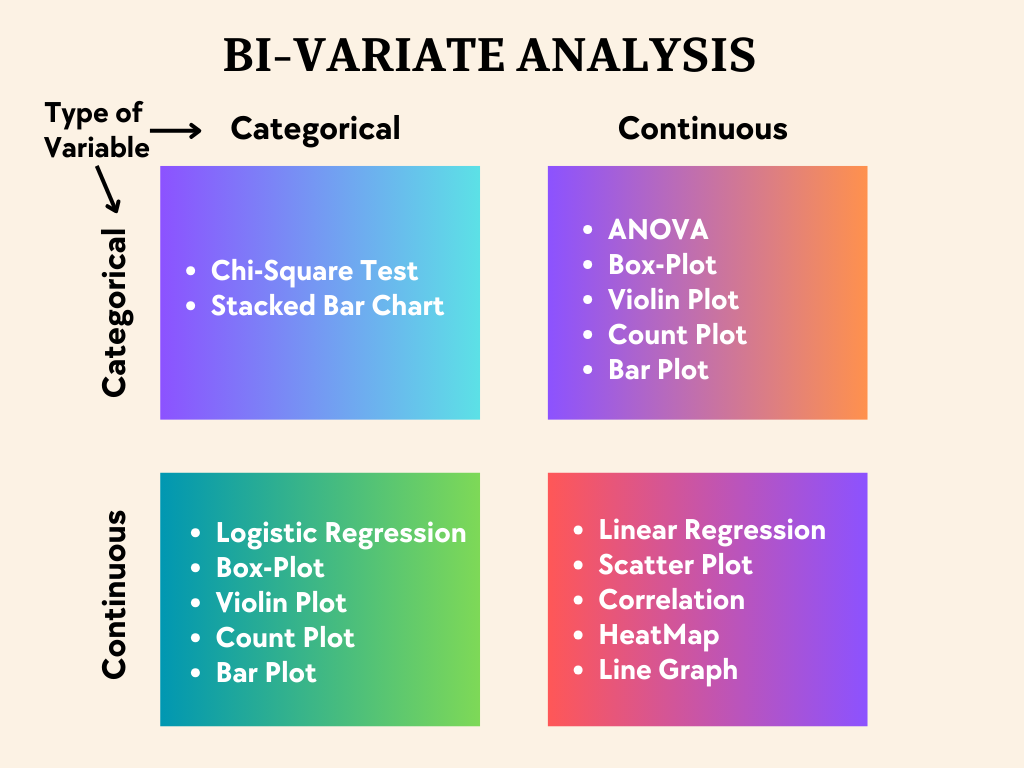
Bivariate Analysis is used to analyze two variables(continuous and categorical) simultaneously and their relationship with each other.
Multivariate Analysis is used to establish a relationship or comparison between more than two variables. 3D scatter Plots are used for multivariate analysis.
Feature Engineering
Feature Engineering is used to modify existing features or create new features for better modeling results. It is also called Data Featurization.
1. Variable Selection or Transformation
Important features are selected for better model results, and sometimes they are transformed for better performance of the model.
Numerical Feature Transformation
For the transformation of numerical features, Feature Scaling is done, which is discussed in the feature scaling section.
Categorical Feature Transformation
There are various encoding methods used for categorical features transformation.
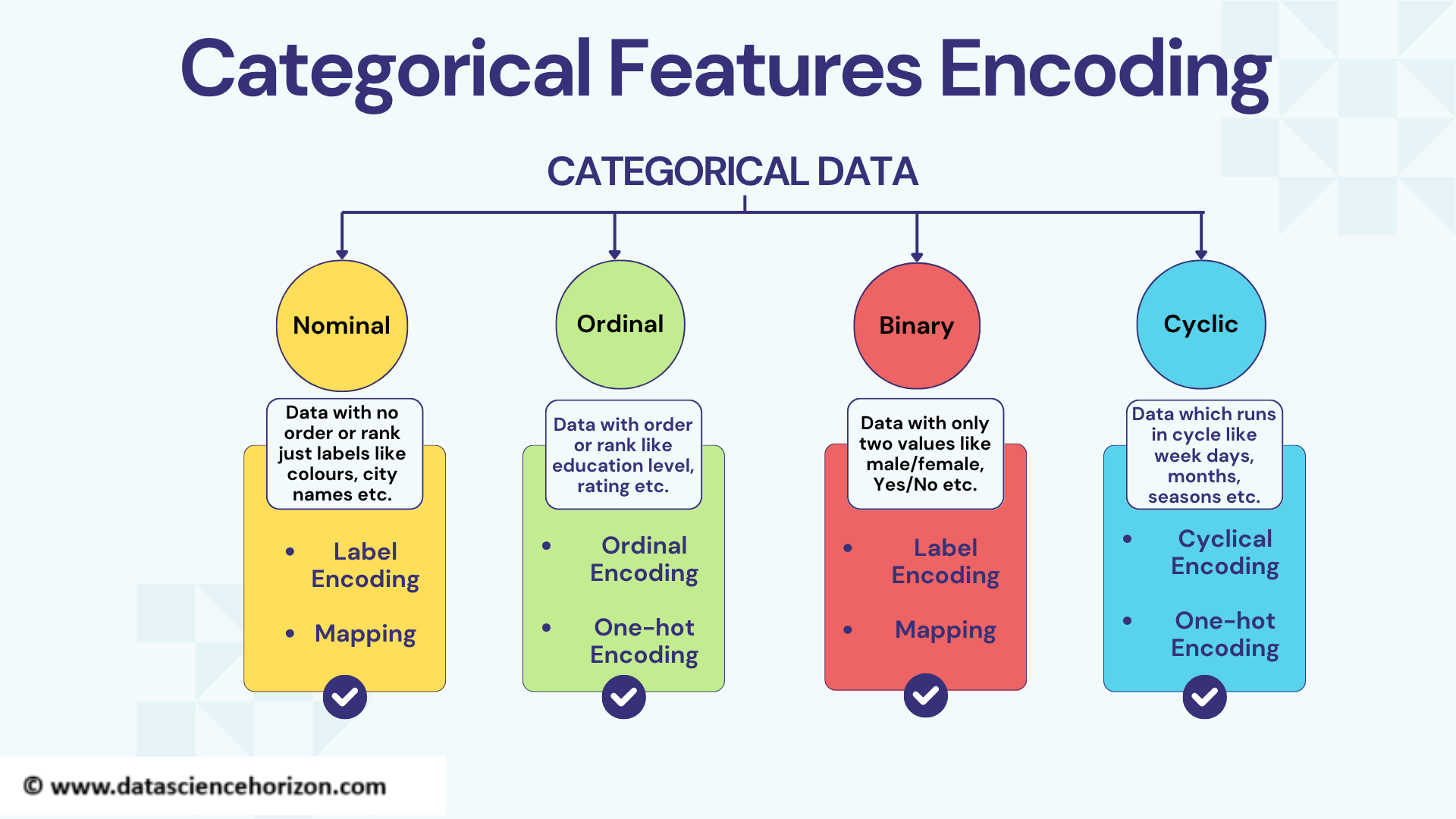
Click here to know about various categorical features and their encoding methods.
2. Variable Creation
New features are created to enhance the predictive power of models.
Remark: I will post a dedicated article on Feature Engineering soon.
Modeling and Evaluation
Modeling and Evaluation a crucial machine learning processes. It involves the following three steps.
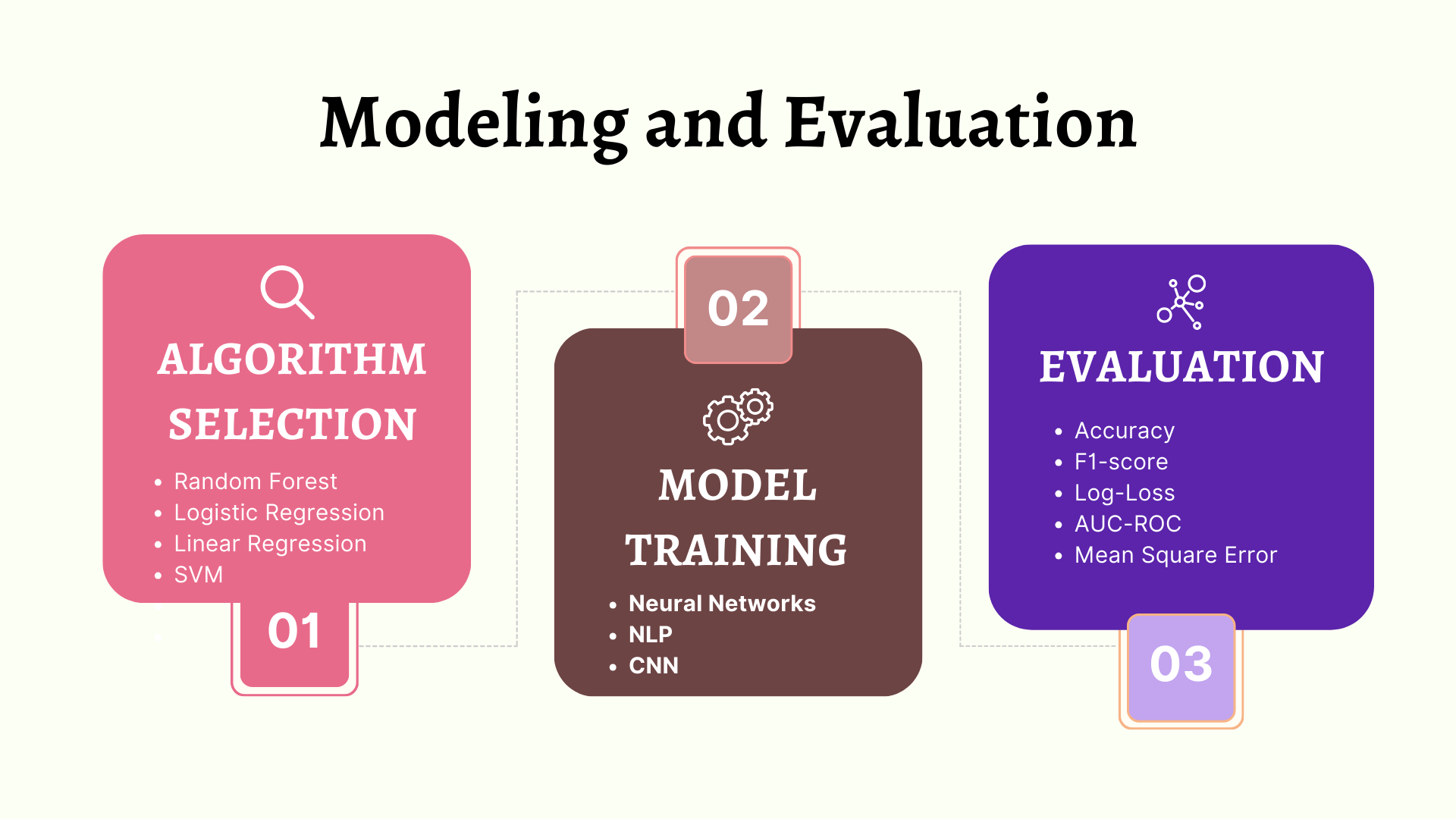
1. Algorithm Selection
In the earlier stages, the problem is identified as a classification problem, a regression problem, or a clustering problem. Then, algorithms are selected based on the nature of the problem.
2. Model Training
The model is trained on the training data using algorithms like KNN, Naive Bayes, Random Forest, Neural Nets, etc. To know about various Machine Learning Algorithms, click here.
To know about Regression Models, click here.
To know about Ensemble Models, click here.
3. Model Evaluation
The evaluation of the model is done on the test data based on the selected performance metrics. For details of the performance metrics for regression, click here, and for classification performance metrics, click here.
Results Communication
At this stage, results, insights, and findings are communicated to the stakeholders. To convey complex information, charts, graphs, and dashboards are used. Jupyter Notebooks or Google Colab are used for code sharing. Tools like Tableau and Power BI are used to show visualizations and reports.
Deployment
Once the results are approved, Models are deployed to a real environment for real-world testing and real-time predictions. Here, models are deployed and their performance is continuously monitored using tools like Amazon SageMaker, Azure ML, Databricks, MLflow, etc.
Real-World Testing
Once the mode is deployed, real-world testing is done in a real environment. Here, the model is continuously tested and monitored to perform effectively over time. A/B testing is effectively used at this stage.
Documentation and Version Control
Here, documents are maintained for all the data science processes, and versions are maintained for various versions of data, models, metadata, and configuration using version control tools like Git, GitHub, and GitLab.
Optimization
Optimization is the step where more data is introduced, and more features are added to improve model performance. Here, failures are handled by retraining the model and code optimization. Based on continuous feedback and changing requirements, the complete data science pipeline is iterated using CI/CD pipelines.
Final Thoughts
We have given an overview of the complete Data Science Project Lifecycle. You can click on the links mentioned to learn each topic in detail.
Stay Tuned!!
We have posted an article on ‘How to become a Data Scientist’. Click on the link below to explore it in detail.
Keep learning and keep implementing!!


Pingback: Data Science with Python: Handling Categorical Features - Data Science Horizon
Very good article… Looking forward for further articles on dis topic
Thanku so much for appreciation
Thanks alot